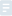Ƕ��ʽ�W���Pӛ��C���������ٌW
�r�g��2018-09-12 ��Դ��δ֪
Ƕ��ʽ�W���Pӛ��C���������ٌW
�r�g��2018-09-12 ��Դ��δ֪
c�������f�Ǿͱ��^�y�ˣ�������c�������@�njW�����y�c����ô��ο��ٌWc�������أ����濂�Y��һЩ����֪�R�c�����������Կ��ٌWŶ��
1.1���x
����ֵ��� ������(��� �΅��� ��� �΅�, ...)
{
�Z��
�Z��
return ����ֵ
}
�����������R��:��һ��Ҫ�ܿ��������Ĺ��ܵĘ��R������ʾ������
����ֵ��ͣ���Ҫ���صķ���ֵ���
������Ҫ����ֵ�r������ֵ��͞�void��return��߅��Ҫ�ӷ���ֵ
������ֵ��͞�ָᘕr���Q��ָᘺ���
�΅�: �����ⲿ�����ľֲ�׃��
����Ҫ���Յ����r, ����void
6.2�������{��
׃�� = ������(����1, ����2, ......);
���������o������׃������ֵ��
�\���^��:���΅��ֿ��g,�ь����xֵ�o�΅�
�\�к����еij���
�����{�ú������\���{���c����һ��
�a��:�ര��:vsp
1.3���������÷���
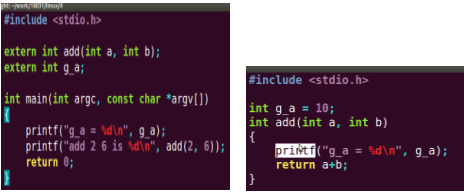
1.3.1 ��ǰ��,�U���x��(extern)
����:
1.3.2 ���ļ��У��{����һ���ļ��ж��x�ĺ���
���g���gcc a.c b.c -g�����g�ɂ��ļ��ĕr������Ȼ��a.out
1.3.3. ��ֹ�e���ļ��{�ñ��ļ��ĺ���(static)
ע��:����statics��Ԓ����ͬ�ļ����ǿ��Դ�����ͬ���ļ����ġ�
stati�����������÷��������ڱ��ļ���
1.4׃�������÷���(�@��Ԕ���Ĵ��_�ȴ����IJ��ּ������v��)
1.4.1. ���x
ȫ��׃�������x�ں������׃����Ҳ��������鶨�x��{}���׃����
�ֲ�׃�������x�ں����ȵ�׃����Ҳ��������鶨�x��{}�ȵ�׃����
��Ҫ���x��{}���_ʼ��
1.4.2 ������(Ĭ�J���÷���)
ȫ��׃�����Ķ��x�_ʼ���ļ��ĽY��
�ֲ�׃�����Ķ��x�_ʼ���c֮ǰһ��������{ }�Y����
ע��:С���÷�����׃�������δ����÷�����׃��
��ጣ�
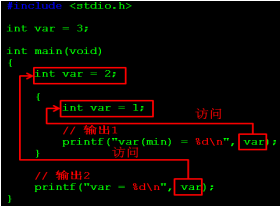

�@��ĔU�����÷�����ᘌ�ȫ��׃�����f�ģ��ֲ�׃�����ܔU��
����:1)ʹ�õ�λ���ڶ��x֮ǰ
2)ʹ�õ�λ���������ļ�
3)����ȫ��׃�������÷�����Ĭ�J������
4)�������������ǏĶ��x�_ʼ�������ļ��Y��(ᘌ��ļ����f)
����:

1.5�ȴ�ķ���
1.5.1.����δ�\�Еr(size a.out���Կ�����Ϣ)
text�����CPU�Ɉ��еęC��ָ����ڳ�����ʹ�ã���ֹ�䱻�����ģ����a�^ͨ����ֻ�x�ġ�
data�� ��ű���ʼ����ȫ��׃�����o�B׃��(ȫ���o�B׃���;ֲ��o�B׃��)����������(���ַ�������)��
Bss�����δ��ʼ����ȫ��׃�� (��ʼ����0��Ӌ��C�����J���@�����˳�ʼ�����������Գ�ʼ����0��ȫ��׃����������bss�^��)
ע�⣺BSS�^�Ĕ����ڳ����_ʼ����֮ǰ���Ⱥ˳�ʼ����0���ָ�(NULL)��
���w��

1.5.2.�����\�Еr
�����\�Еrռ��5���^�����a�^����ʼ�������^/�o�B�����^��δ��ʼ�������^���х^�����^
(1)���a�^(text)
���a�^ָ����������OӋ�������Έ��У��������ָ��tֻ������һ�Σ�������ͣ��t��ʹ�����Dָ�����M���f�w���t��������팍�F��
���a�^���������a��Ҫ�����Č���(����ĵ�ַ����)�������������(�����w�Ĕ�ֵ����2)����ֱ�Ӱ����ڴ��a��;����Ǿֲ����������ڗ��з�����g��Ȼ������ԓ�����ĵ�ַ;�����BSS�^�͔����^���ڴ��a��ͬ������ԓ�����ĵ�ַ��
(2) ȫ�ֳ�ʼ�������^/�o�B�����^(data)
�ھ��g�ĕr��͕���ʼ��������ֻ��ʼ��һ�Ρ������ѽ��f�^���ڳ����g�r��ԓ�^���ѽ���������ˣ��@�K�ȴ��ڳ���������\�����g�����ڣ�������Y���r���ŕ���ጷš�
(3)δ��ʼ������ �^(BSS)�����\�Еr��׃��ֵ����ʼ��0�����ʼ����
(4)���^(stack)
��ź����ą���ֵ�;ֲ�׃�����ɾ��g���Ԅӷ���ጷţ��������ʽ����ڔ����Y���ė��������c�Dz���Ҫ����Tȥ���]�ȴ�����Ć��}���ܷ���;ͬ�r�������������ޣ���Linuxϵ�y�У���������ֻ��8M�����Ү������ķ����Y���r(�纯��)���ֲ�׃���Ͳ�����ʹ�á�
(5)�х^(heap)
��Щ��������ֻ���ڳ����\�Еr���ܴ_�����@�Ӿ��g���ھ��g�r�͟o���������A�ȷ�����g��ֻ�г����\�Еr�ŷ��䣬�@���DŽӑB�ȴ���䡣�х^�������ڄӑB�ȴ����(��malloc�ĄӑB�ȴ����)�����ڃȴ���λ��bss�^�͗��^֮�g��һ���ɳ���T��Ո��ጷ�(freeጷŻ����ֹͣ)��
������
ע�⣺
(1):�х^�ăȴ���Ҫ����T�Լ�ጷš�
(2):���^�ڷ����Y���r�����g���͕�ጷ��ˣ�����Ҫע�◣�^�Д������������ڡ�
(3):���^�������ޣ�ע�ⲻҪʹ�ó���ֲ�׃�������糬�M��
(4):bss�^�еĔ������㲻�M�г�ʼ����Ԓ��ϵ�y�����҂���ʼ����0���������^��Ĕ�����ϵ�y�������҂���ʲô������ע��х^�͗��^�еĔ�����δ����ʼ����׃���t�п������K������
1.6׃������������
1.6.1���
1. data��bss�е�׃�����������ڣ�������_ʼ������ĽY����==>ȫ��׃�����o�B(ȫ��/�ֲ�)׃��
2. ���е�׃�����������ڣ��������_ʼ�������ĽY����==>�ֲ�׃�����΅�
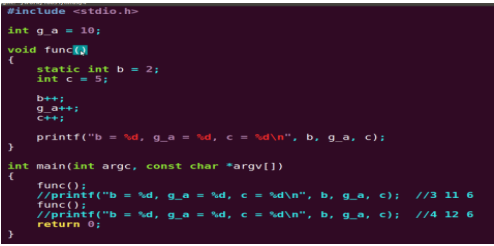
6.6.2���o�B�ֲ�׃�����f����
�Еrϣ�������еľֲ�׃����ֵ�ں����{�ýY������ʧ������ԭֵ������ռ�õĴ惦��Ԫ��ጷţ�����һ��ԓ�����{�Õr��ԓ׃��������һ�κ����{�ýY���r��ֵ���@�r�͑�ԓָ��ԓ�ֲ�׃�����o�B�ֲ�׃��(static local variable)��
(1) �o�B�ֲ�׃�����o�B�惦�^�ȷ���惦��Ԫ���ڳ��������\�����g����ጷš����Ԅ�׃��(���ӑB�ֲ�׃��)���ڄӑB�惦e���惦�ڄӑB�惦�^���g(�������o�B�惦�^���g)�������{�ýY����ጷš�
(2) ���o�B�ֲ�׃���x��ֵ���ھ��g�r�M��ֵ�ģ���ֻ�x��ֵһ�Σ��ڳ����\�Еr�����г�ֵ���Ժ�ÿ���{�ú����r���������x��ֵ��ֻ�DZ����ϴκ����{�ýY���r��ֵ�������Ԅ�׃���x��ֵ�������ھ��g�r�M�еģ������ں����{�Õr�M�У�ÿ�{��һ�κ������½oһ�γ�ֵ���ஔ�ڈ���һ���xֵ�Z�䡣
(3) ����ڶ��x�ֲ�׃���r���x��ֵ��Ԓ�����o�B�ֲ�׃�����f�����g�r�Ԅ��x��ֵ0(����ֵ��׃��)����ַ�(���ַ���׃��)�������Ԅ�׃�����f��������x��ֵ���t����ֵ��һ�����_����ֵ���@������ÿ�κ����{�ýY����惦��Ԫ��ጷţ��´��{�Õr������������惦��Ԫ����������Ć�Ԫ�е�ֵ�Dz��_���ġ�
(4) �mȻ�o�B�ֲ�׃���ں����{�ýY������Ȼ���ڣ������������Dz����������ģ�Ҳ�����f������������������“����Ҋ”�ġ�
���w��ጣ�
��ʼ��ȫ��׃��δ��ʼ��ȫ��׃���ֲ�׃���o�Bȫ��׃���o�B�ֲ�׃��
ռ�ô惦���gdata
bss��datadata
��ʼ���Δ���ʼ��һ��
��ʼ��һ��ÿ���{�ö���ʼ����ʼ��һ�γ�ʼ��һ��
������Ĭ�J�����ɔU��Ĭ�J�����ɔU��Ĭ�J������Ĭ�J������Ĭ�J������
�������ڳ����_ʼ->����Y�� �����_ʼ->����Y�����x�_ʼ�������Y�������_ʼ->����Y�������_ʼ->����Y��
�a�䣺register׃��
register int r_local = 6;Ҫ���g���M�����ڼĴ�����register׃���Dz�����ȡ��ַ������
registerʹ�üĴ���׃���������ٶȣ�Ҳ�������f�҂��M���ܵض�ض��xregister׃�����ܼӿ������\���ٶȣ�����CPU�мĴ��������ģ�
������׃��ָ����register׃������ζ�������ڄe����;�ļĴ����͜p���ˣ�������\��a�������g�Y���������đ����ֺ��l����
�ڼĴ����������r�£�ֻ�ý����ڃȴ棬�@�ӷ��������ͳ�����\���ٶȡ�
�ڬF���C�汾�У�����ћ]�ж��xregister׃���ı�Ҫ����龎�g�������register������������Ĵ�����ʹ����r��׃������r�Q���Ƿ��׃����ጞ�register׃����
1.7��������
1.7.1 ָᘅ���
�a�䣺߀�зN���È�����������Ҫʹ�ýY���w���酢���ĕr������΅����ĵ��Ǘ��Ŀ��g�����Ŀ��g�����ģ�����Y���w���^��һ�㲻���hֱ�ӌ��Y���w�����΅�������ͨ�^ָᘌ����M���L����
1.7.2 ���M����
int atoil(char str[10])
int atoil(char str[])
int atoil(char *str)
�@���N���x����ʽ��ͬ�������_����Ч����һģһ�ӵģ�����ʹ����һ�N���x�����g�����������D�Q�ɵ����N��ʽ��
1.8ָᘺ��� VS ����ָ�
1.8.1 ָᘺ���(pointfunc.c)
�_��������
(1)�_��Ŀ����� int buf[5]
(2)�_��ָ���� ��Ŀ����ͻ��A�ϼ�* ����׃����λ�� int (*)[5]
(3)���xָ�׃�� int (*p)[5]
������


1.8.2 ����ָᘣ�������ָᘣ�ָ����Ǻ�����
(1) ���x
void swap(int *a, int *b)
void (*pfunc)(int *, int *);
(2) �xֵ
pfunc = &swap;
pfunc = swap; (������, ���Ǻ�����ָᘳ���)
ע�⣺������ͺͺ���ָ���ͼ��ݣ���߅�ɷN���x��ʽ�����S���x��ʹ��
(3) �{��
(*pfunc)(&a, &b);//��swap����ɺ���
pfunc(&a, &b); //��swap����ɺ���ָᘣ��@�ɷN�{���S���x����߅�Ķ��x�Ǜ]���Pϵ�ġ�
������
�a�䣺strcmp ���^�ַ�����С qsort ���Կ�������
�÷���
shrcmp
strcmp()������ͨ�^�ɂ��ַ���һ��һ���ַ����^��(�����^�Δ���ڶ����������L��+1)
����strcmp("hello","here");
���ȱ��^��һ���ַ�'h'= 'h'���
�������^�ڶ����ַ�'e'= 'e'���
���^�������ַ� 'l'>'e',����һ����ֵ
����ַ�����ȫ��ȕ���0
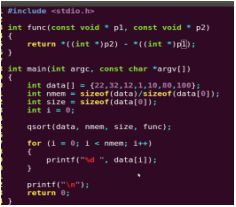
qsort��
qsort���f�ܔ��M���������Ҫ�W��ʹ�ã����εĔ��M��Ȼ�����f���@����ҪӑՓһ���ַ������M��ʹ�á�
���ȿ�һ��qsort��ԭ�ͣ�
void qsort(void *base, size_t nmemb, size_t size,
int(*compar)(const void *, const void *));
���_ʹ���@������Ҫע����c��
1.baseҪ�����M����ַ
2.size������ÿ��Ԫ�صĴ�С
3.���_����compar����
�����nj��H���ã�
һ���ַ������M��*str[MAX],���O����F�ڱ�����n���ַ����ˡ�
����Ҫ���_����ʲô���ַ������M�����ε��f�����������������һ�����M��ֻ���^���е�Ԫ����һ���ַ��������L���@Щ�ַ���������ָᘣ�Ҳ���������ĵ�ַ������*name[]={"james","henry"}����ô�L�����е��ַ�������name[0],name[1]...�@����Ђ��������ĵط��ˣ������ַ������M����ôÿ��Ԫ�صĴ�С�����Ƕ�����?��name[0]���f���������ַ���“james”���L��5��߀��char*�Ĵ�С4��?�𰸑�ԓ��4������ַ������M���汣����Ǹ����ַ�����ָᘣ����Իص��������f�ĵڶ��cע�⣬��qsort�ĕr��ԓҪ��sizeof(char *);
�ڶ�������compar�������^�ַ����еط�Ҫע�⣺
���ܰ�strcmp������oqsort�������܌�strcmp(p,q),����΅���const void*��ͣ�ͬ��������strcmp((char *)p, (char *)q);Ҳ�ǟoЧ��;���_�Č�����ԓ��:strcmp(*(char **)p, *(char **)q);�ȏ����D�Q��char**,����*�p��һ���g�ӌ�ַ������
int compar_words(const void *p, const void *q)
{
return strcmp(*(char **)p, *(char **)q);
}
��������đ��ã����ʹ��qsort��ԓ���@�ӣ�
qsort(str, n, sizeof(char *), compar);
���������^���M�е��ַ����Ĵ�С


1.9�f�w����
���x��ֱ�ӻ��g���{���Լ�
ע�⣺�f�w�����Ч�ʱ��^�ͣ����gռ�õ�Ҳ�ܶ࣬Ψһ�������DZ��^��������
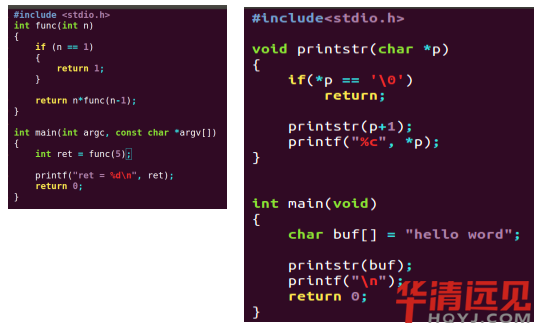
��: ���ú����f�w���Fn!
1. �����f�wͨ��헣�n! = n * (n - 1)!
2. �����f�w�Y���l����n = 1
3. ���a���F�����O�����ѽ����ã��������{�ã���Ҫȥ��Ӌ��C���еľ��w�^��
4. �β�����, ���Ո�������
���������F�A�� ��ݔ����ַ�������ݔ����