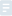C�Z�Գ��������㷨
�r�g��2018-01-08 ��Դ��δ֪
C�Z�Գ��������㷨
�r�g��2018-01-08 ��Դ��δ֪
���������ЃȲ�������ⲿ���Ȳ������ǔ���ӛ��ڃȴ����M�������ⲿ������������Ĕ����ܴ�һ�β����ݼ{ȫ��������ӛ䛣��������^������Ҫ�L����档
�҂��@���f�f�˴�������ǃȲ�����
��n�^�t�����Õr�g���s�Ȟ�O(nlog2n)���������������������w��������������Ŀǰ���ڱ��^�ăȲ������б��J���Ǻõķ���������������P�I�����S�C�ֲ��r�����������ƽ���r�g��;
1. ��������—ֱ�Ӳ�������(Straight Insertion Sort)
����˼��:
��һ��ӛ䛲��뵽������õ�������У��Ķ��õ�һ���£�ӛ䛔���1��������������Ȍ����еĵ�1��ӛ䛿�����һ������������У�Ȼ��ĵ�2��ӛ������M�в��룬ֱ���������������ֹ��
Ҫ�c���O���ڱ��������R�r�惦���Д����M߅��֮�á�
ֱ�Ӳ�������ʾ����

�����Ҋһ���Ͳ���Ԫ����ȵģ���ô����Ԫ�ذ�������Ԫ�ط������Ԫ�صĺ��档���ԣ����Ԫ�ص�ǰ�����]�и�׃����ԭ�o�����г�ȥ���������ź�����������Բ��������Ƿ����ġ�
�㷨�Č��F��
//��������Ч�ʣ�
�r�g���s�ȣ�O(n^2).
�����IJ��������ж��ֲ�������2-·��������
2. ��������—ϣ������(Shell`s Sort)
ϣ��������1959 ����D.L.Shell ������ģ�����ֱ���������^��ĸ��M��ϣ�������ֽпsС��������ϣ�������ǷǷ��������㷨��
����˼�룺
ϣ�������ǰ�ӛ䛰��˵�һ�������ֽM����ÿ�Mʹ��ֱ�Ӳ��������㷨����;�S��������u�p�٣�ÿ�M�������P�I�~Խ��Խ�࣬�������p��1�r�������ļ�ǡ���ֳ�һ�M���㷨��Kֹ��
����������
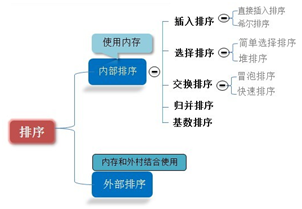
�����^�̣���ȡһ��������d1<n����������̖���d1�Ĕ��MԪ�ط�һ�M���M���M��ֱ�Ӳ�������;Ȼ��ȡd2<d1���؏������ֽM���������;ֱ��di=1��������ӛ䛷��Mһ���M�������ֹ��
�㷨���F��
�҂�����̎���������У���������d = {n/2 ,n/4, n/8 .....1} n��Ҫ���Ă���
�����Ȍ�Ҫ�����һ�Mӛ䛰�ij������d(n/2,n��Ҫ���Ă���)�ֳ����ɽM�����У�ÿ�M��ӛ䛵������d.��ÿ�M��ȫ��Ԫ���M��ֱ�Ӳ�������Ȼ������һ���^С������(d/2)�����M�зֽM����ÿ�M�����M��ֱ�Ӳ��������^�m����sС����ֱ����1����ʹ��ֱ�Ӳ��������������
//shell����
void Shell_Sort(int *list,int count)
{
int i,j;
int temp;
int num= count;
do
{
num= num/2;
for(i = num;i<count;i++)
{
if(list[i]<list[i-num])
{
temp = list[i];
for(j=i-num;j>=0&&list[j]>temp;j-=num)
{
list[j+num] = list[j];
}
list[j+num] = temp;
}
}
}while(num>1);
}
ϣ������rЧ�������y���P�I�a�ı��^�Δ��cӛ��ƄӴΔ���ه��������������d���xȡ���ض���r�¿��Ԝʴ_������P�I�a�ı��^�Δ���ӛ䛵��ƄӴΔ���Ŀǰ߀�]���˽o���xȡ�õ������������еķ����������������п����и��Nȡ������ȡ�攵�ģ�Ҳ��ȡ�|���ģ�����Ҫע�⣺���������г�1 ��]�й����ӣ��Һ�һ���������ӱ�횞�1��ϣ��������һ����������������ϣ������r�g���s�ȵ��½���n*log2n������еȴ�СҎģ���F���á�
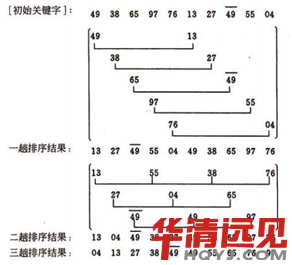
3. �x������—�����x������(Simple Selection Sort)
����˼�룺
��Ҫ�����һ�M���У��x��С(���ߴ�)��һ�����c��1��λ�õĔ����Q;Ȼ����ʣ�µĔ���������С(���ߴ�)���c��2��λ�õĔ����Q��������ƣ�ֱ����n-1��Ԫ��(�����ڶ�����)�͵�n��Ԫ��(��һ����)���^��ֹ��
�����x�������ʾ����
�M�б��^�����ĕr�g���s�Ȟ�O(n^2)���M���ƄӲ����ĕr�g���s�Ȟ�O(n)�������x�������Dz���������
����������
��һ�ˣ���n ��ӛ����ҳ��P�I�aС��ӛ��c��һ��ӛ䛽��Q;
�ڶ��ˣ��ĵڶ���ӛ��_ʼ��n-1 ��ӛ������x���P�I�aС��ӛ��c�ڶ���ӛ䛽��Q;
�Դ����.....
��i �ˣ��t�ĵ�i ��ӛ��_ʼ��n-i+1 ��ӛ����x���P�I�aС��ӛ��c��i ��ӛ䛽��Q��
ֱ���������а��P�I�a����
�㷨���F��
//�x������
void Select_Sort(int *list,int count)
{
int min,i,j;
for(i=0;i<count;i++)
{
min = i;
for(j=i+1;j<count;j++)
{
if(list[min]>list[j])
{
min = j;
}
}
if(min!=i)
{
swap(list[i],list[min]);
}
}
}
�����x������ĸ��M——��Ԫ�x������
�����x������ÿ��ѭ�hֻ�ܴ_��һ��Ԫ�������Ķ�λ���҂����Կ��]���M��ÿ��ѭ�h�_���ɂ�Ԫ��(��ǰ�˴��Сӛ�)��λ��,�Ķ��p�����������ѭ�h�Δ������M��n�������M������ֻ���M��[n/2]��ѭ�h���ɡ�
4. �x������—������(Heap Sort)
��������һ�N�����x�������nj�ֱ���x���������Ч���M��
����˼�룺
�ѵĶ��x���£�����n��Ԫ�ص�����(k1,k2,...,kn),���҃H���M��
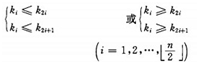
�r�Q֮��ѡ��ɶѵĶ��x���Կ��������Ԫ��(����һ��Ԫ��)�؞�С�(С픶�)��
����һ�S���M�惦һ���ѣ��t�ь���һ����ȫ����䣬�����з��~�Y�c��ֵ��������(��С��)����Ů��ֵ�����Y�c(���Ԫ��)��ֵ��С(���)�ġ��磺
(a)��픶����У�(96��83��27��38��11��09)
(b)С픶����У�(12��36��24��85��47��30��53��91)
��ʼ�r��Ҫ�����n���������п�����һ�����惦�Ķ����(һ�S���M�惦�����)���{�������Ĵ惦��ʹ֮�ɞ�һ���ѣ������Ԫ��ݔ�����õ�n ��Ԫ����С(���)��Ԫ�أ��@�r�ѵĸ����c�Ĕ�С(���ߴ�)��Ȼ��ǰ��(n-1)��Ԫ�������{��ʹ֮�ɞ�ѣ�ݔ�����Ԫ�أ��õ�n ��Ԫ���д�С(��δ�)��Ԫ�ء�������ƣ�ֱ��ֻ�Ѓɂ����c�Ķѣ��������������Q����õ���n�����c���������С��Q�@���^�̞������
��ˣ����F���������Q�ɂ����}��
1. ��Ό�n ��������Ĕ����ɶ�;
2. ݔ�����Ԫ�غ������{��ʣ��n-1 ��Ԫ�أ�ʹ��ɞ�һ���¶ѡ�
����ӑՓ�ڶ������}��ݔ�����Ԫ�غ�ʣ��n-1Ԫ�����½��ɶѵ��{���^�̡�
�{��С픶ѵķ�����
1)�O��m ��Ԫ�صĶѣ�ݔ�����Ԫ�غ�ʣ��m-1 ��Ԫ�ء����ѵ�Ԫ��������((��һ��Ԫ���c����M�н��Q)���ѱ��Ɖģ���ԭ��H�Ǹ��Y�c���M��ѵ����|��
2)�����Y�c�c�����Ә����^СԪ�ص��M�н��Q��
3)���c���Ә佻�Q��������Ә�ѱ��Ɖģ������Ә�ĸ��Y�c���M��ѵ����|���t�؏ͷ��� (2).
4)���c���Ә佻�Q��������Ә�ѱ��Ɖģ������Ә�ĸ��Y�c���M��ѵ����|���t�؏ͷ��� (2).
5)�^�m�����M������|���Ә��M���������Q������ֱ���~�ӽY�c���ѱ����ɡ�
�Q�@���Ը��Y�c���~�ӽY�c���{���^�̞�Y�x����D��
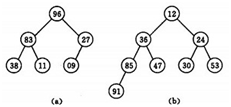
��ӑՓ��n ��Ԫ�س�ʼ���ѵ��^�̡�
���ѷ���������ʼ���н��ѵ��^�̣�����һ�������M�кY�x���^�̡�
1)n ���Y�c����ȫ����䣬�t��һ���Y�c�ǵڂ��Y�c���Ә䡣
2)�Y�x�ĵڂ��Y�c������Ә��_ʼ��ԓ�Ә�ɞ�ѡ�
3)֮����ǰ���Ό����Y�c������Ә��M�кY�x��ʹ֮�ɞ�ѣ�ֱ�����Y�c��
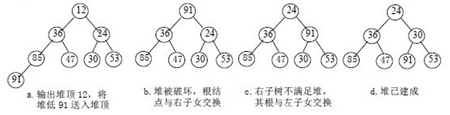
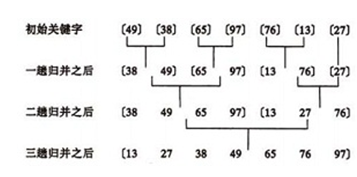
��D���ѳ�ʼ�^�̣��o�����У�(49��38��65��97��76��13��27��49)
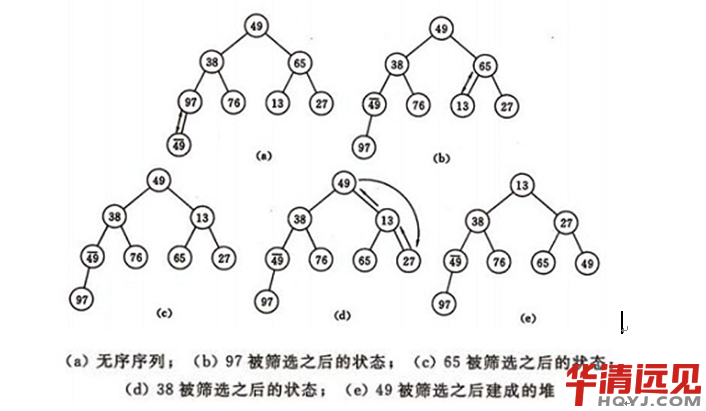
�㷨�Č��F��
���㷨������������������Ҫ�ɂ��^�̣�һ�ǽ����ѣ����Ƕ���c�ѵĺ�һ��Ԫ�ؽ��Qλ�á����Զ������Ѓɂ������M�ɡ�һ�ǽ��ѵĝB���������Ƿ����{�ÝB�������F����ĺ�����
//�{����һ����
void Heap_Adjust(int *list,int s,int m)
{
int temp = list[s];
for(int j=2*s+1;j<=m;j = 2*j+1)
{
if(list[j]<list[j+1]&&j<m)
{
j++;
}
if(temp>list[j])
break;
list[s] = list[j];
s = j;
}
list[s] = temp;
}
//������
void Heap_Sort(int *list,int len)
{
//����һ����픶�
for(int s = len/2-1;s>=0;s--)
{
Heap_Adjust(list,s,len-1);
}
//����
for(int i = len-1;i >= 1;i--)
{
swap(list[0],list[i]);
Heap_Adjust(list,0,i-1);
}
}
����:
�O����Ȟ�k�����ĸ����~�ĺY�x��Ԫ�ر��^�Δ�����2(k-1)�Σ����Qӛ�����k �Ρ����ԣ��ڽ��öѺ������^���еĺY�x�Δ������^��ʽ��
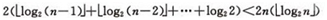
�����ѕr�ı��^�Δ������^4n �Σ���˶��������r�£��r�g���s��Ҳ�飺O(nlogn )��
���ڽ���ʼ������ı��^�Δ��^�࣬���Զ������m����ӛ䛔��^�ٵ��ļ����������Ǿ͵������o�����g��O(1)�����Dz�������������
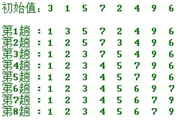
5. ���Q����—ð������(Bubble Sort)
����˼�룺
��Ҫ�����һ�M���У�����ǰ߀δ�ź���ķ����ȵ�ȫ���������϶��������ăɂ��������M�б��^���{�����^��Ĕ����³����^С������ð������ÿ���������Ĕ����^��l�F�����������c����Ҫ���෴�r���͌��������Q��
ð�������ʾ����

�㷨�Č��F��
//����
void Bubble_Sort(int *list,int count)
{
int flag = true;
int i = 0,j = 0;
for(i=0;i<=count&&flag;i++)
{
flag = false;
for(j=count -1;j>=i;j--)
{
if(list[j]<list[j-1])
{
swap(list[j],list[j-1]);
flag = true;
}
}
}
}
ð�������㷨�ĸ��M
��ð������Ҋ�ĸ��M�����Ǽ���һ��־��׃��exchange�����ژ�־ijһ�������^�����Ƿ��Д������Q������M��ijһ������r���]���M�Д������Q���t�f�������ѽ���Ҫ�����кã��������Y�������ⲻ��Ҫ�ı��^�^�̡��������ṩ���ɷN���M�㷨��
1.�O��һ��־��׃��pos,����ӛ�ÿ�������к�һ���M�н��Q��λ�á�����posλ��֮���ӛ䛾��ѽ��Q��λ,�����M����һ������rֻҪ���赽posλ�ü��ɡ�
2.���yð��������ÿһ���������ֻ���ҵ�һ����ֵ��Сֵ,�҂����]������ÿ���������M������ͷ���ɱ�ð�ݵķ���һ�ο��Եõ��ɂ��Kֵ(���ߺ�С��) , �Ķ�ʹ�����˔����p����һ�롣
6. ���Q����—��������(Quick Sort)
����˼�룺
һ�˿���������㷨�ǣ�
1)�O�Ãɂ�׃��i��j�������_ʼ�ĕr��i=0��j=N-1;
2)�Ե�һ�����MԪ�������P�I�������xֵ�okey����key=A[0];
3)��j�_ʼ��ǰ���������ɺ��_ʼ��ǰ����(j--)���ҵ���һ��С��key��ֵA[j]����A[j]��A[i]���Q;
4)��i�_ʼ�������������ǰ�_ʼ�������(i++)���ҵ���һ������key��A[i]����A[i]��A[j]���Q;
5)�؏͵�3��4����ֱ��i=j; (3,4���У��]�ҵ����ϗl����ֵ����3��A[j]��С��key,4��A[i]������key�ĕr���׃j��i��ֵ��ʹ��j=j-1��i=i+1��ֱ���ҵ���ֹ���ҵ����ϗl����ֵ���M�н��Q�ĕr��i�� jָ�λ�ò�׃�����⣬i==j�@һ�^��һ��������i+��j-��ɵĕr�˕r��ѭ�h�Y��)��
(a)һ��������^�̣�


�㷨�Č��F��
//��������
int Partition(int *list,int low,int high)
{
int pivotKey;
pivotKey = list[low];
while(low<high)
{
while(low<high&&list[high]>=pivotKey)
{
high--;
}
swap(list[low],list[high]);
while(low<high&&list[low]<=pivotKey)
{
low++;
}
swap(list[low],list[high]);
}
return low;
}
void Qsort(int *list,int low,int high)
{
int pivot;
if(low<high)
{
pivot =Partition(list,low,high);
Qsort(list,low,pivot-1);
Qsort(list,pivot+1,high);
}
}
void Quick_Sort(int *list,int count)
{
Qsort(list,0,count-1);
}
������
����������ͨ�����J����ͬ������(O(nlog2n))��������ƽ�����ܺõġ�������ʼ���а��P�I�a������������r��������͑����ð��������M֮��ͨ����“����ȡ�з�”���xȡ����ӛ䛣���������^�g�ăɂ����c�c���c����ӛ��P�I�a���е��{����֧�cӛ䛡�����������һ����������������
��������ĸ��M
�ڱ����M�㷨��,ֻ���L�ȴ���k���������f�w�{�ÿ�������,ԭ���л�������Ȼ���ٌ������������������ò��������㷨�����`�C�������M����㷨�r�g���s���������ͣ��Ү�kȡֵ�� 8 ���ҕr,���M�㷨�����ܼѡ�
7. �w������(Merge Sort)
����˼�룺
�w��(Merge)�����nj��ɂ�(��ɂ�����)������ϲ���һ���µ�����������Ѵ��������з֞����ɂ������У�ÿ��������������ġ�Ȼ���ٰ����������кϲ������w�������С�
�w������ʾ����
�ϲ�������
�Or[i…n]�Ƀɂ������ӱ�r[i…m]��r[m+1…n]�M�ɣ��ɂ��ӱ��L�ȷքe��n-i +1��n-m��
1.j=m+1;k=i;i=i; //�Ãɂ��ӱ�����ʼ�˼��o�����M����ʼ��
2.��i>m ��j>n���D�� //����һ���ӱ��Ѻϲ��꣬���^�xȡ�Y��
3.//�xȡr[i]��r[j]�^С�Ĵ����o�����Mrf
���r[i]<r[j]��rf[k]=r[i]; i++; k++; �D��
��t��rf[k]=r[j]; j++; k++; �D��
4.//����δ̎������ӱ���Ԫ�ش���rf
���i<=m����r[i…m]����rf[k…n] //ǰһ�ӱ��ǿ�
���j<=n , ��r[j…n] ����rf[k…n] //��һ�ӱ��ǿ�
5.�ϲ��Y����
//�w������
//���ɂ����M����
void Merge(int *list,int start,int mid,int end)
{
const int len1 = mid -start +1;
const int len2 = end -mid;
const int len = end - start +1;
int i,j,k;
int * front = (int *)malloc(sizeof(int)*len1);
int * back = (int *)malloc(sizeof(int)*len2);
for(i=0;i<len1;i++)
front[i] = list[start+i];
for(j=0;j<len2;j++)
back[j] = list[mid+j+1];
for(i=0,j=0,k=start;i<len1&&j<len2&&k<end;k++)
{
if(front[i]<back[j])
{
list[k] = front[i];
i++;
}
else
{
list[k] = back[j];
j++;
}
}
while(i<len1)
{
list[k++] = front[i++];
}
while(j<len2)
{
list[k++] = back[j++];
}
}
void MSort(int *list,int start,int end)
{
if(start<end)
{
int mid = (start+end)/2;
MSort(list,0,mid);
MSort(list,mid+1,end);
Merge(list,start,mid,end);
}
}
void Merge_Sort(int *list,int count)
{
MSort(list,0,count-1);
}
8. Ͱ����/��������(Radix Sort)
�f��������֮ǰ���҂����fͰ����
����˼��(Ͱ����)��
�nj���зֵ����ޔ�����Ͱ���ÿ��Ͱ���ق��e����(�п�����ʹ�Äe�������㷨�������f�ط�ʽ�^�mʹ��Ͱ�����M������)��Ͱ���������������һ�N�w�{�Y������Ҫ���������ЃȵĔ�ֵ�Ǿ������ĕr��Ͱ����ʹ�þ��ԕr�g(Θ(n))����Ͱ������ ���^���������ܵ� O(n log n) ����Ӱ푡�
�����f�����ǰє����ֽM������һ������Ͱ�У�Ȼ��ÿ��Ͱ��������M������
����Ҫ����С��[1..1000]�����ȵ�n������A[1..n]����
���ȣ�����Ͱ�O���С��10�ķ��������w���ԣ��O����B[1]�惦[1..10]������������B[2]�惦(10..20]��������……����B[i]�惦((i-1)*10, i*10]��������i = 1,2,..100��������100��Ͱ��
Ȼ��A[1..n]���^��β����һ�飬��ÿ��A[i]���댦����ͰB[j]�С��ٌ��@100��Ͱ��ÿ��Ͱ��Ĕ��������@�r����ð�ݣ��x���������ţ�һ����f�κ��������ԡ�
������ݔ��ÿ��Ͱ����Ĕ��֣���ÿ��Ͱ�еĔ��֏�С����ݔ�����@�Ӿ͵õ����Д����ź����һ�������ˡ�
���O��n�����֣���m��Ͱ�����������ƽ���ֲ��ģ��tÿ��Ͱ����ƽ����n/m�����֡������ÿ��Ͱ�еĔ��ֲ��ÿ���������ô�����㷨�ď��s����
O(n+ m * n/m*log(n/m)) = O(n + nlogn - nlogm)
����ʽ��������m�ӽ�n�ĕr��Ͱ������s�Ƚӽ�O(n)
��Ȼ�����Ϗ��s�ȵ�Ӌ���ǻ���ݔ���n��������ƽ���ֲ��@�����O�ġ��@�����O�Ǻ��ģ����H������Ч�����]���@ô�á�������еĔ��ֶ�����ͬһ��Ͱ�У��Ǿ��˻���һ��������ˡ�
ǰ���f�Ď״������㷨 ���֕r�g���s�ȶ���O(n2)��Ҳ�в��������㷨�r�g���s����O(nlogn)����Ͱʽ����s�܌��FO(n)�ĕr�g���s�ȡ���Ͱ�����ȱ�c�ǣ�
1)�����ǿ��g���s�ȱ��^�ߣ���Ҫ���~���_�N�������Ѓɂ����M�Ŀ��g�_�N��һ����Ŵ����M��һ���������^��Ͱ�����������ֵ�Ǐ�0��m-1���Ǿ���Ҫm��Ͱ���@��Ͱ���M��Ҫ����m�����g��
2)��δ������Ԫ�ض�Ҫ��һ���ķ����ȵȵȡ�
Ͱʽ������һ�N����������������ض��Dz���Ҫ�M���P�I�a�ı��^����ǰ����Ҫ֪���������е�һЩ���w��r��
��������Ļ���˼�룺�f���˾����M�ж�ε�Ͱʽ����
���������^�̟o횱��^�P�I�֣�����ͨ�^“����”��“�ռ�”�^�́팍�F���������ĕr�g���s�ȿ��_�������A��O(n)��
����:
�������52 ���ƣ��ɰ���ɫ����ֵ�ֳɃɂ��ֶΣ����С�Pϵ�飺
��ɫ�� ÷��< ���K< �t��< ����
��ֵ�� 2 < 3 < 4 < 5 < 6 < 7 < 8 < 9 < 10 < J < Q < K < A
����ư���ɫ����ֵ�M���������õ��������У�

���ɏ��ƣ�����ɫ��ͬ����Փ��ֵ���ӣ���ɫ�͵��Ǐ���С�ڻ�ɫ�ߵģ�ֻ����ͬ��ɫ��r�£���С�Pϵ������ֵ�Ĵ�С�_�����@���Ƕ��P�I�a����
��õ�����Y�����҂�ӑՓ�ɷN������
����1���Ȍ���ɫ������֞�4 ���M����÷���M�����K�M���t�ĽM�����ĽM���ٌ�ÿ���M�քe����ֵ�M������4 ���M�B���������ɡ�
����2���Ȱ�13 ����ֵ�o��13 ����̖�M(2 ̖��3 ̖��...��A ̖)�����ư���ֵ���η��댦���ľ�̖�M���ֳ�13 �ѡ��ٰ���ɫ�o��4 ����̖�M(÷�������K���t�ġ�����)����2̖�M����ȡ���քe���댦����ɫ�M���ٌ�3 ̖�M����ȡ���քe���댦����ɫ�M��……���@�ӣ�4 ����ɫ�M�о�����ֵ����Ȼ��4 ����ɫ�M�����B���������ɡ�
�On ��Ԫ�صĴ������а���d ���P�I�a{k1��k2��…��kd}���t�Q���Ќ��P�I�a{k1��k2��…��kd}������ָ�������������ɂ�ӛ�r[i]��r[j](1≤i≤j≤n)���M�����������Pϵ��
����k1 �Q����λ�P�I�a��kd �Q���λ�P�I�a ��
�ɷN���P�I�a������
���P�I�a�����Տ���λ�P�I�a����λ�P�I�a��Ĵ�λ����λ�P�I�a�����������փɷN������
�����(Most Significant Digit first)�������QMSD ����
1)�Ȱ�k1 ����ֽM�������зֳ����������У�ͬһ�M���е�ӛ��У��P�I�ak1 ��ȡ�
2)�ٌ����M��k2 ����ֳ��ӽM��֮��������P�I�a�^�m�@�ӵ�����ֽM��ֱ������λ�P�I�akd �����ӽM�����
3)�ٌ����M�B����������õ�һ���������С�����ư���ɫ����ֵ�����н�B�ķ���һ����MSD ����
�����(Least Significant Digit first)�������QLSD ����
1) �ȏ�kd �_ʼ�����ٌ�kd-1�M�����������؏ͣ�ֱ����k1����ֽM�ֳ�С�������к�
2) �����������B����������ɵõ�һ�����������, ����ư���ɫ����ֵ�����н�B�ķ���������LSD ����
����LSD�������ʽ��������Ļ���˼��
“���P�I������”��˼�댍�F“���P�I������”���������ͻ��ַ��͵Ć��P�I�֣����Կ����ɶ�����λ������ַ����ɵĶ��P�I�֣��˕r���Բ���“����-�ռ�”�ķ����M�������@һ�^�̷Q��������������ÿ�����ֻ��ַ����ܵ�ȡֵ�����Q����������磬����ƵĻ�ɫ������4����ֵ������13�����������ƕr���ȿ����Ȱ���ɫ������Ҳ�����Ȱ���ֵ����������ɫ����r���Ȱ��t���ڡ������������ֳ�4��(����)���ٰ�������ٯB����һ��(�ռ�)��Ȼ����ֵ�����ֳ�13��(����)���ٰ������B����һ��(�ռ�)������M�ж��η�����ռ����Ɍ��������������
��������:
�ǰ��յ�λ������Ȼ���ռ�;�ٰ��ո�λ����Ȼ�����ռ�;������ƣ�ֱ����λ���Еr����Щ�������Ѓ��ȼ����ģ��Ȱ��̓��ȼ������ٰ��߃��ȼ�����Ĵ�����Ǹ߃��ȼ��ߵ���ǰ���߃��ȼ���ͬ�ĵ̓��ȼ��ߵ���ǰ������������ڷքe���քe�ռ��������Ƿ����ġ�
�㷨���F��
#define MAX 20
#define BASE 10
void Radix_Sort(int *a, int n)
{
int i, b[MAX], m = a[0], exp = 1;
for (i = 1; i < n; i++)
{
if (a[i] > m)
{
m = a[i];
}
}
while (m / exp > 0)
{
int bucket[BASE] = { 0 };
for (i = 0; i < n; i++)
{
bucket[(a[i] / exp) % BASE]++;
}
for (i = 1; i < BASE; i++)
{
bucket[i] += bucket[i - 1];
}
for (i = n - 1; i >= 0; i--)
{
b[--bucket[(a[i] / exp) % BASE]] = a[i];
}
for (i = 0; i < n; i++)
{
a[i] = b[i];
}
exp *= BASE;
}
}
���Y:
���N����ķ����ԣ��r�g���s�ȺͿ��g���s�ȿ��Y��

�҂����^�r�g���s�Ⱥ�������r��
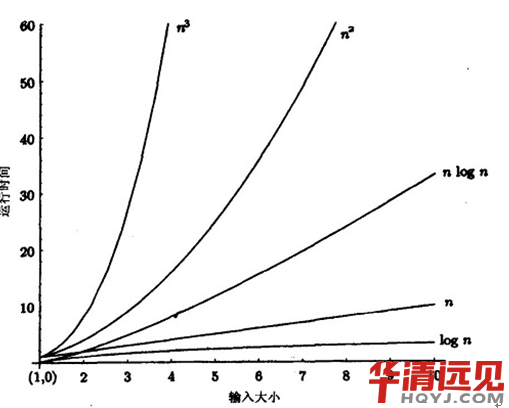
�r�g���s�Ⱥ���O(n)�����L��r
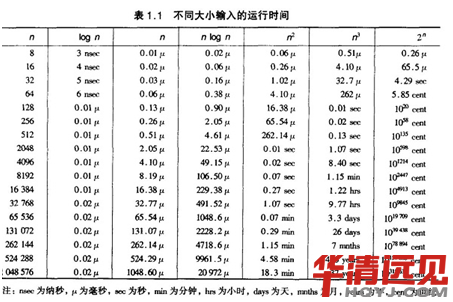
���Ԍ�n�^�������ӛ䛡�һ����x���Ǖr�g���s�Ȟ�O(nlog2n)��������
�r�g���s�ȁ��f��
(1)ƽ���A(O(n2))����
���������:ֱ�Ӳ��롢ֱ���x���ð������;
(2)���Ԍ����A(O(nlog2n))����
������������͚w������;
(3)O(n1+§))����,§�ǽ���0��1֮�g�ij�����
ϣ������
(4)�����A(O(n))����
����������߀��Ͱ��������
�f����
��ԭ��������������r��ֱ�Ӳ��������ð�������p�ٱ��^�Δ����Ƅ�ӛ䛵ĴΔ����r�g���s�ȿɽ���O(n);����������t�෴����ԭ����������r����͑����ð�����r�g���s����ߞ�O(n2);ԭ���Ƿ����������x���������w������ͻ�������ĕr�g���s��Ӱ푲���
�����ԣ�
�����㷨�ķ�����:��������������У����ڶ���������ͬ�P�I�ֵ�ӛ䛣����^���� �@Щӛ䛵��������ֲ�׃���t�Qԓ�㷨�Ƿ�����;���������ӛ䛵����� ����l���˸�׃���t�Qԓ�㷨�Dz������ġ�
�����Եĺ�̎�������㷨����Ƿ����ģ���ô��һ���I������Ȼ���ُ���һ���I������һ���I����ĽY�����Ԟ�ڶ����I�������á�������������@�ӣ��Ȱ���λ������ΰ���λ����λ��ͬ��Ԫ��������ٸ�λҲ��ͬ�r�Dz�����׃�ġ����⣬��������㷨���������Ա������ı��^;
�����������㷨��ð�����������w������ͻ�������
���Ƿ����������㷨���x������������ϣ����������
�x�������㷨�ʄt��
ÿ�N�����㷨�����Ѓ�ȱ�c����ˣ��ڌ��Õr�������ͬ��r�m���x�ã��������Ԍ���N�����Y������ʹ�á�
�x�������㷨������
Ӱ�����������кܶ࣬ƽ���r�g���s�ȵ͵��㷨����һ�����ǃ��ġ��෴���Еrƽ���r�g���s�ȸߵ��㷨���ܸ��m��ijЩ������r��ͬ�r���x���㷨�r߀�ÿ��]���Ŀ��x�ԣ�������ܛ���ľS�o��һ����ԣ���Ҫ���]���������������c��
1.�������ӛ䛔�Ŀn�Ĵ�С;
2.ӛ䛱��픵�����Ĵ�С��Ҳ����ӛ��г��P�I�����������Ϣ���Ĵ�С;
3.�P�I�ֵĽY������ֲ���r;
4.�������Ե�Ҫ��
�O������Ԫ�صĂ�����n.
1)��n�^�t�����Õr�g���s�Ȟ�O(nlog2n)���������������������w��������
����������Ŀǰ���ڱ��^�ăȲ������б��J���Ǻõķ���������������P�I�����S�C�ֲ��r�����������ƽ���r�g��;
����������ȴ���g���S��Ҫ���Եģ�
�w����������һ�������Ĕ����Ƅӣ������҂������^�c��������M�ϣ��ȫ@��һ���L�ȵ����У�Ȼ���ٺϲ�����Ч���ό�������ߡ�
2)��n�^�ȴ���g���S����Ҫ���� =���w������
3)��n�^С���ɲ���ֱ�Ӳ����ֱ���x������
ֱ�Ӳ�������Ԫ�طֲ�����ֱ�Ӳ��������p�ٱ��^�Δ����Ƅ�ӛ䛵ĴΔ���
ֱ���x������ ��Ԫ�طֲ����������Ҫ���ԣ��x��ֱ���x������
4)һ�㲻ʹ�û�ֱ��ʹ�Â��y��ð������
5)��������
����һ�N�����������㷨������һ���ľ����ԣ�
1���P�I�ֿɷֽ⡣
2��ӛ䛵��P�I��λ���^�٣�����ܼ�����
3������ǔ��֕r�����ǟo��̖�ģ���t������������ӳ����s�ȣ����Ȍ�����ؓ���_����